Unsupervised Cross-modal Synthesis of Subject-specific Scans
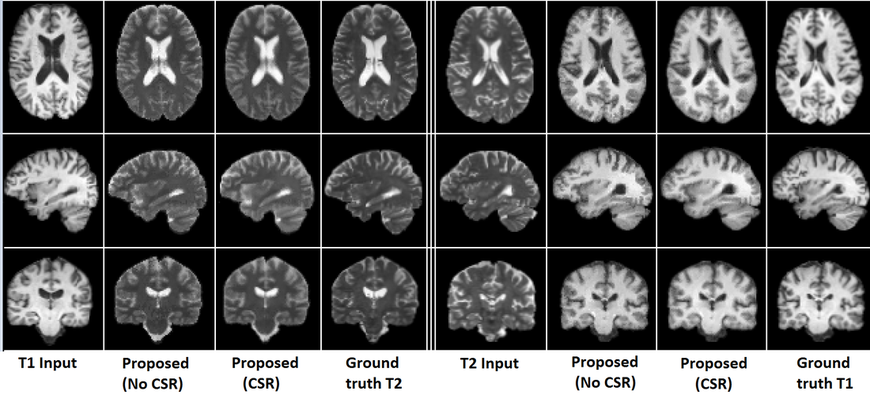
Abstract: Recently, cross-modal synthesis of subject-specific scans has been receiving significant attention from the medical imaging community. Though various synthesis approaches have been introduced in the recent past, most of them are either tailored to a specific application or proposed for the supervised setting, i.e., they assume the availability of training data from the same set of subjects in both source and target modalities. But, collecting multiple scans from each subject is undesirable. Hence, to address this issue, we propose a general unsupervised cross-modal medical image synthesis approach that works without paired training data. Given a source modality image of a subject, we first generate multiple target modality candidate values for each voxel independently using cross-modal nearest neighbor search. Then, we select the best candidate values jointly for all the voxels by simultaneously maximizing a global mutual information cost function and a local spatial consistency cost function. Finally, we use coupled sparse representation for further refinement of synthesized images. Our experiments on generating T1-MRI brain scans from T2-MRI and vice versa demonstrate that the synthesis capability of the proposed unsupervised approach is comparable to various state-of-the-art supervised approaches in the literature.
Contributions:
- We propose a general unsupervised approach for cross-modal synthesis of subject-specific scans. The proposed approach does not require paired training data from the source and target modalities. To the best of our knowledge, this is the first approach that addresses the cross-modal medical image synthesis problem in an unsupervised setting.
- We formulate the cross-modal image synthesis task as an optimization problem that jointly maximizes the mutual information between the given source modality and the synthesized target modality images, and the spatial consistency among neighboring voxels in the synthesized target image.
- We show that the proposed approach can also be used in the supervised setting by replacing the cross-modal nearest neighbor search with source-modal nearest neighbor search. Under the supervised setting, the proposed approach outperforms various state-of-the-art approaches .
Experiments:
- Synthesized T1-MRI scans from T2-MRI scans and vice versa.
- Used T1 and T2 scans of 19 subjects from NAMIC brain multimodality database.
- Followed leave-one-out cross-validation setting (18 subjects for training and 1 subject for testing).
|
|
Publications:
Raviteja Vemulapalli, Hien Van Nguyen, and Shaohua Kevin Zhou, "Unsupervised Cross-modal Synthesis of Subject-specific Scans", ICCV, 2015.
[PDF][Supplementary]
[PDF][Supplementary]
Book chapters:
Raviteja Vemulapalli, Hien Van Nguyen, and Shaohua Kevin Zhou, "Deep Networks and Mutual Information Maximization for Cross-modal Medical Image Synthesis", Elsevier's book on Deep Learning for Medical Image Analysis. [LINK]
Patents:
Raviteja Vemulapalli, Hien Van Nguyen, and Shaohua Kevin Zhou, "Method and System for Unsupervised Cross-Modal Medical Image Synthesis", US Patent 9,582,916, issued February 28, 2017.
