Preprints
Raviteja Vemulapalli, Hadi Pouransari, Fartash Faghri, Sachin Mehta, Mehrdad Farajtabar, Mohammad Rastegari, Oncel Tuzel, "Knowledge Transfer from Vision Foundation Models for Efficient Training of Small Task-specific Models", arXiv:2311.18237, 2024. [PDF]
Mohammad Samragh, Mehrdad Farajtabar, Sachin Mehta, Raviteja Vemulapalli, Fartash Faghri, Devang Naik, Oncel Tuzel, Mohammad Rastegari, "Weight subcloning: direct initialization of transformers using larger pretrained ones", arXiv:2312.09299, 2023. [PDF]
Mohammadreza Salehi, Mehrdad Farajtabar, Maxwell Horton, Fartash Faghri, Hadi Pouransari, Raviteja Vemulapalli, Oncel Tuzel, Ali Farhadi, Mohammad Rastegari, Sachin Mehta, "CLIP meets Model Zoo Experts: Pseudo-Supervision for Visual Enhancement", arXiv:2310.14108, 2023. [PDF]
Publications
Karren D Yang, Anurag Ranjan, Jen-Hao Rick Chang, Raviteja Vemulapalli, Oncel Tuzel, Probabilistic Speech-Driven 3D Facial Motion Synthesis: New Benchmarks, Methods, and Applications", CVPR, 2024. [PDF]
Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel, "MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training", CVPR, 2024. [PDF]
Haoxiang Wang, Pavan Kumar Anasosalu Vasu, Fartash Faghri, Raviteja Vemulapalli, Mehrdad Farajtabar, Sachin Mehta, Mohammad Rastegari, Oncel Tuzel, Hadi Pouransari, "SAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding", eLVM workshop, CVPR, 2024. [PDF]
Saurabh Garg, Mehrdad Farajtabar, Hadi Pouransari, Raviteja Vemulapalli, Sachin Mehta, Oncel Tuzel, Vaishaal Shankar, Fartash Faghri, "TiC-CLIP: Continual Training of CLIP Models", ICLR, 2024. [PDF]
Hsuan Su, Ting-Yao Hu, Hema Swetha Koppula, Raviteja Vemulapalli, Jen-Hao Rick Chang, Karren Yang, Gautam Varma Mantena, Oncel Tuzel, "Corpus Synthesis for Zero-shot ASR domain Adaptation using Large Language Models", ICASSP 2024. [PDF]

Pengfei Guo, Warren R. Morningstar, Raviteja Vemulapalli, Karan Singhal, Vishal M. Patel, Philip A. Mansfield, "Towards Federated Learning Under Resource Constraints via Layer-wise Training and Depth Dropout", PML4DC workshop, ICLR, 2023.[PDF]
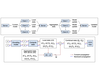
Raviteja Vemulapalli, Warren R. Morningstar, Philip A. Mansfield, Hubert Eichner, Karan Singhal, Arash Afkanpour, Bradley Green, "Federated Training of Dual Encoding Models on Small Non-IID Client Datasets", Trustworthy ML workshop, ICLR, 2023. [PDF]

Xiangyun Zhao, Raviteja Vemulapalli, Philip Mansfield, Boqing Gong, Bradley Green, Lior Shapira, Ying Wu, "Contrastive Learning for Label-Efficient Semantic Segmentation", ICCV 2021. [PDF]

Bardia Doosti, Ching-Hui Chen, Raviteja Vemulapalli, Xuhui Jia, Yukun Zhu, Bradley Green, "Boosting Image-based Mutual Gaze Detection using Pseudo 3D Gaze", AAAI 2021.
[PDF][Dataset]
[PDF][Dataset]
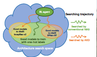
Yu Liu, Xuhui Jia, Mingxing Tan, Raviteja Vemulapalli, Yukun Zhu, Bradley Green, Xiaogang Wang, "Search to Distill: Pearls are Everywhere but not the Eyes", CVPR 2020. (ORAL) [PDF]

Raviteja Vemulapalli, Aseem Agarwala, "A Compact Embedding for Facial Expression Similarity", CVPR, 2019.
[PDF][Dataset]
[PDF][Dataset]

Mehdi S. M. Sajjadi, Raviteja Vemulapalli, Matthew Brown, "Frame-Recurrent Video Super-Resolution", CVPR, 2018.
[PDF]
[PDF]

Raviteja Vemulapalli, Oncel Tuzel, Ming-Yu Liu, Rama Chellappa, "Gaussian Conditional Random Field Network for Semantic Segmentation", CVPR, 2016. (SPOTLIGHT)
[PDF][Supplementary][Poster][Results video]
[PDF][Supplementary][Poster][Results video]

- Raviteja Vemulapalli, Oncel Tuzel, Ming-Yu Liu, "Deep Gaussian Conditional Random Field Network: A Model-based Deep Network for Discriminative Denoising", CVPR, 2016.
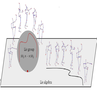
Raviteja Vemulapalli, Rama Chellappa, "Rolling Rotations for Recognizing Human Actions from 3D Skeletal Data", CVPR, 2016.
[PDF][Poster][Code]
[PDF][Poster][Code]
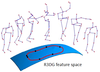
Raviteja Vemulapalli, Felipe Arrate, Rama Chellappa, "R3DG Features: Relative 3D Geometry-based Skeletal Representations for Human Action Recognition", Computer Vision and Image Understanding 152: 155-166 (2016). [PDF]
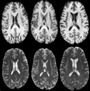
Raviteja Vemulapalli, Hien Van Nguyen, Shaohua Kevin Zhou, "Unsupervised Cross-modal Synthesis of Subject-specific Scans", ICCV, 2015.
[PDF][Supplementary][Poster]
[PDF][Supplementary][Poster]
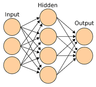
Hien Van Nguyen, Shaohua Kevin Zhou, Raviteja Vemulapalli, "Cross-Domain Synthesis of Medical Images Using Efficient Location-Sensitive Deep Network", MICCAI, 2015.
[PDF]
[PDF]
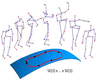
Raviteja Vemulapalli, Felipe Arrate, Rama Chellappa, "Human Action Recognition by Representing 3D Human Skeletons as Points in a Lie Group", CVPR, 2014.
[PDF][Presentation: PPT or PDF][Poster][Code] (ORAL)
[PDF][Presentation: PPT or PDF][Poster][Code] (ORAL)
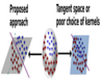
Raviteja Vemulapalli, Jaishanker K. Pillai, Rama Chellappa, "Kernel Learning for Extrinsic Classification of Manifold Features ", CVPR, 2013.
[PDF][Poster][Presentation]
[PDF][Poster][Presentation]

Raviteja Vemulapalli, R. Aravind, "Spatio-Temporal Nonparametric Background Modeling and Subtraction", ICCV Workshop on Visual Surveillance, 2009.
[PDF][Presentation]
[PDF][Presentation]

Raviteja Vemulapalli, Luis Salgado, "Video Synchronization Based on Displacements of Center of Motion", Annual IEEE India Conference (INDICON), 2009.
[PDF]
[PDF]
Technical reports
- Yu-Chuan Su, Raviteja Vemulapalli, Ben Weiss, Chun-Te Chu, Philip A. Mansfield, Lior Shapira, Colvin Pitts, "Camera View Adjustment Prediction for Improving Image Composition", arXiv:2104.07608, 2021. [PDF]
- Zhuoran Shen, Irwan Bello, Raviteja Vemulapalli, Xuhui Jia, Ching-Hui Chen, "Global Self-Attention Networks for Image Recognition", arXiv:2010.03019, 2020. [PDF]
- Kota Hara, Raviteja Vemulapalli, Rama Chellappa, "Designing Deep Convolutional Neural Networks for Continuous Object Orientation Estimation", arXiv:1702.01499, 2017. [PDF]
- Raviteja Vemulapalli, David W Jacobs, "Riemannian Metric Learning for Symmetric Positive Definite Matrices", arXiv:1501.02393, 2015. [PDF]
- Raviteja Vemulapalli, Vinay Praneeth Boda, Rama Chellappa, "Multiple Kernel Learning for Ratio-trace Problems via Convex Optimization", arXiv:1410.4470, 2014. [PDF]
Book chapters
Raviteja Vemulapalli, Hien Van Nguyen, Shaohua Kevin Zhou, "Deep Networks and Mutual Information Maximization for Cross-modal Medical Image Synthesis", Elsevier's book on Deep Learning for Medical Image Analysis, 2017. [LINK]
PhD thesis
"Geometric Representations and Deep Gaussian Conditional Random Field Networks for Computer Vision", August 2016, University of Maryland, College Park. [PDF][Presentation]
